|
Improving Generative Adversarial Network Generalization for Facial Expression Synthesis
with Arbish Akram and Arif Mahmood
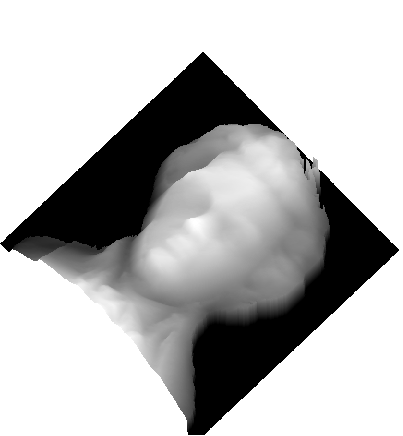
Facial expression synthesis aims to generate realistic facial expressions while preserving identity. Existing conditional generative adversarial networks (GANs) achieve excellent image-to-image translation results, but their performance often degrades when test images differ from the training dataset. We present Regression GAN (RegGAN), a model that learns an intermediate representation to improve generalization beyond the training distribution. RegGAN consists of two components: a regression layer with local receptive fields that learns expression details by minimizing the reconstruction error through a ridge regression loss, and a refinement network trained adversarially to enhance the realism of generated images.
We train RegGAN on the CFEE dataset and evaluate its generalization performance both on CFEE and challenging out-of-distribution images, including celebrity photos, portraits, statues, and avatar renderings. For evaluation, we employ four widely used metrics: Expression Classification Score (ECS) for expression quality, Face Similarity Score (FSS) for identity preservation, QualiCLIP for perceptual realism, and Fr\'echet Inception Distance (FID) for assessing both expression quality and realism. RegGAN outperforms six state-of-the-art models in ECS, FID, and QualiCLIP, while ranking second in FSS. Human evaluations indicate that RegGAN surpasses the best competing model by 25\% in expression quality, 26\% in identity preservation, and 30\% in realism.
Arbish Akram, Nazar Khan, and Arif Mahmood. Improving Generative Adversarial Network Generalization for Facial Expression Synthesis Multimedia Tools and Applications, February 2, 2026, DOI: https://doi.org/10.1007/s11042-026-21213-w
[ArXiv]
[DOI]
[Bib]
|

|
Hand-drawn cadastral map parsing, stitching and assembly via jigsaw puzzles
with Tauseef Iftikhar
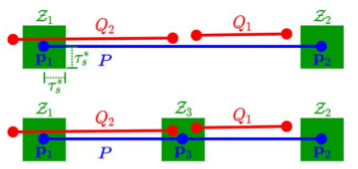
We present a robust method for parsing the content of hand-drawn cadastral maps in order to obtain high-resolution, digitized assemblies of larger regions from individual maps. The parsing phase involves solving a challenging background grid detection plem. We exploit the geometry of detected grids for stitching overlapping map images. A novel method for computing geometric compatibilities between non-overlapping map pieces is also introduced. It is shown to be important since existing chromatic compatibility measures are not as useful for hand-drawn maps. Assembly of maps involves solving an arbitrary-boundary jigsaw puzzle problem with non-overlapping pieces of the same rectangular shape. It corresponds to finding a maximum spanning graph within a multigraph whose edge weights are the piece compatibilities. Since the problem is NP-hard, we develop a polynomial time approximation algorithm that involves two distinct greedy decisions at each iteration. In contrast to existing evaluation metrics for fixed-boundary jigsaw puzzles, we present an F1-score based evaluation scheme for the arbitrary-boundary jigsaw problem that evaluates relative placements of pieces instead of absolute locations. On a testing set of 218 images of 109 cadastral maps comprising 15 different map assembly problems, we achieve a high average F1-score of 0.88. Results validate our compatibility measure as well as the two-stage greedy nature of our method. An ablation study isolates the importance of individual modules of the developed pipeline.
Tauseef Iftikhar and Nazar Khan. Hand-drawn cadastral map parsing, stitching and assembly via jigsaw puzzles. International Journal on Document Analysis and Recognition (IJDAR), May 14, 2024, DOI: https://doi.org/10.1007/s10032-024-00465-y
[SharedIt]
[DOI]
[Bib]
|
|
ELSM: Evidence-Based Line Segment Merging
with Naila Hamid and Arbish Akram
Existing line segment detectors break perceptually contiguous linear structures into multiple line segments. This can be offset by re-merging the segments but existing merging algorithms over-merge and produce globally incorrect segments. Geometric cues are necessary but not sufficient for deciding whether to merge two segments or not. By restricting the result of any merging decision to have underlying image support, we reduce over-merging and globally incorrect segments. We propose a novel measure for evaluating merged segments based on line segment Hausdorff distance. On images from YorkUrbanDB, we show that our algorithm improves both qualitative and quantitative results obtained from four existing line segment detection methods and is better than two existing line segment merging methods. Our method does not suffer from inconsistent results produced by four recent deep learning based models. The method is easily customisable to work for line drawings such as hand-drawn maps to obtain vectorised representations.
Naila Hamid, Nazar Khan, Arbish Akram, ELSM: Evidence-Based Line Segment Merging, The Computer Journal, March 23, 2024, DOI: https://doi.org/10.1093/comjnl/bxae021
[Project page]
[DOI]
[Manuscript]
[Bib]
[Code]
|

|
Background grid extraction from historical hand-drawn cadastral maps
with Tauseef Iftikhar
We tackle a novel problem of detecting background grids in hand-drawn cadastral maps. Grid extraction is necessary for accessing and contextualizing the actual map content. The problem is challenging since the background grid is the bottommost map layer that is severely occluded by subsequent map layers. We present a novel automatic method for robust, bottom-up extraction of background grid structures in historical cadastral maps. The proposed algorithm extracts grid structures under significant occlusion, missing information, and noise by iteratively providing an increasingly refined estimate of the grid structure. The key idea is to exploit periodicity of background grid lines to corroborate the existence of each other. We also present an automatic scheme for determining the 'gridness' of any detected grid so that the proposed method self-evaluates its result as being good or poor without using ground truth. We present empirical evidence to show that the proposed gridness measure is a good indicator of quality. On a dataset of 268 historical cadastral maps with resolution 1424 x 2136 pixels, the proposed method detects grids in 247 images yielding an average root-mean-square error (RMSE) of 5.0 pixels and average intersection over union (IoU) of 0.990. On grids self-evaluated as being good, we report average RMSE of 4.39 pixels and average IoU of 0.991. To compare with the proposed bottom-up approach, we also develop three increasingly sophisticated top-down algorithms based on RANSAC-based model fitting. Experimental results show that our bottom-up algorithm yields better results than the top-down algorithms. We also demonstrate that using detected background grids for stitching different maps is visually better than both manual and SURF-based stitching.
Tauseef Iftikhar and Nazar Khan. Background grid extraction from historical hand-drawn cadastral maps. International Journal on Document Analysis and Recognition (IJDAR), Dec, 2023, DOI: https://doi.org/10.1007/s10032-023-00457-4
[SharedIt]
[DOI]
[Bib]
|

|
LSRF: Localized and Sparse Receptive Fields for Linear Facial Expression Synthesis based on Global Face Context
with Arbish Akram
Existing generative adversarial network-based methods for facial expression synthesis require larger datasets for training. Their performance drops noticeably when trained on smaller datasets. Moreover, they demand higher computational and spatial complexity at testing time which makes them unsuitable for resource-constrained devices. To overcome these limitations, this paper presents a linear formulation to learn Localized and Sparse Receptive Fields (LSRF) for facial expression synthesis considering global face context. In this perspective, we extend the sparsity-inducing formulation of the Orthogonal Matching Pursuit (OMP) algorithm with a locality constraint to ensure that i) each output pixel observes a localized region and ii) neighboring output pixels attend proximate regions of the input face image. Extensive qualitative and quantitative experiments demonstrate that the proposed method generates more realistic facial expressions and outperforms existing methods. Further, the proposed method can be trained by employing significantly smaller datasets and generalizes well on out-of-distribution images.
Akram, Arbish, and Nazar Khan. LSRF: Localized and Sparse Receptive Fields for Linear Facial Expression Synthesis based on Global Face Context Multimedia Tools and Applications, September 16, 2023, DOI: https://doi.org/10.1007/s11042-023-16822-8
[SharedIt]
[DOI]
[Bib]
[Code and pre-trained models]
|

|
US-GAN: On the importance of Ultimate Skip Connection for Facial Expression Synthesis
with Arbish Akram
We demonstrate the benefit of using an ultimate skip (US) connection for facial expression synthesis using generative adversarial networks (GAN). A direct connection transfers identity, facial, and color details from input to output while suppressing artifacts. The intermediate layers can therefore focus on expression generation only. This leads to a light-weight US-GAN model comprised of encoding layers, a single residual block, decoding layers, and an ultimate skip connection from input to output. US-GAN has 3x fewer parameters than state-of-the-art models and is trained on 2 orders of magnitude smaller dataset. It yields 7% increase in face verification score (FVS) and 27% decrease in average content distance (ACD). Based on a randomized user-study, US-GAN outperforms the state of the art by 25% in face realism, 43% in expression quality, and 58% in identity preservation.
Akram, Arbish, and Nazar Khan. US-GAN: On the importance of Ultimate Skip Connection for Facial Expression Synthesis. Multimedia Tools and Applications, June 6, 2023, DOI: https://doi.org/10.1007/s11042-023-15268-2
[SharedIt]
[DOI]
[arXiv]
[Bib]
[Code and pre-trained model]
|

|
Line Extraction in Handwritten Documents via Instance Segmentation
with Adeela Islam and Tayaba Anjum
Extraction of text lines from handwritten document images is important for downstream text recognition
tasks. It is challenging since handwritten documents do not follow strict rules. Significant variations
in line, word, and character spacing and line skews are acceptable as long as the text remains
legible. Traditional rule-based methods that work well for printed documents do not carry over to
the handwritten domain. In this work, lines are treated as objects to leverage the power of deep
learning based object detection and segmentation frameworks. A key benefit of learnable models is
that lines can be implicitly defined through annotations of training images which allows unwanted
textual content to be ignored when required. A deep instance segmentation model trained in endto-end fashion without any dataset-specific pre- or post-processing achieves 0.858 pixel IU and
0.899 line IU scores averaged over 9 different datasets comprising a wide variety of handwritten
scripts, layouts, page backgrounds, line orientations, and inter-line spacings. It achieves state-of-the-art
results on DIVA-HisDB, VML-AHTE, and READ-BAD datasets and almost state-of-the-art results
on Digital Peter, ICDAR2015-HTR, ICDAR2017, and Bozen datasets. We also introduce a new,
annotated dataset for Urdu script. Our model trained only on Urdu generalizes to multiple other
scripts indicating that it learns a script-invariant representation of text lines. All code, pre-trained
models, and the new Urdu dataset can be accessed at https://github.com/AdeelaIslam/HLExt-via-IS.
Adeela Islam, Tayaba Anjum, and Nazar Khan. Line Extraction in Handwritten Documents via Instance Segmentation. International Journal on Document Analysis and Recognition (IJDAR), May, 2023, DOI: https://doi.org/10.1007/s10032-023-00438-7
[SharedIt]
[DOI]
[Bib]
[Code, data and pre-trained models]
|


|
CALText: Contextual Attention Localization for Offline Handwritten Text
with Tayaba Anjum
Recognition of Arabic-like scripts such as Persian and Urdu is more
challenging than Latin-based scripts. This is due to the presence of a
two-dimensional structure, context-dependent character shapes, spaces
and overlaps, and placement of diacritics. We present an attention based
encoder-decoder model that learns to read handwritten text in context.
A novel localization penalty is introduced to encourage the model to
attend only one location at a time when recognizing the next character.
In addition, we comprehensively refine the only complete and publicly
available handwritten Urdu dataset in terms of ground-truth annotations.
We evaluate the model on both Urdu and Arabic datasets. For
Urdu, contextual attention localization achieves 82.06% character
recognition rate and 51.97% word recognition rate which represent more than
2x improvement over existing bi-directional LSTM models. For Arabic,
the model outperforms multi-directional LSTM models with 77.47%
character recognition rate and 37.66% word recognition rate without
performing any slant or skew correction. Code and pre-trained models
for this work are available at https://github.com/nazar-khan/CALText.
Tayaba Anjum and Nazar Khan. CALText: Contextual Attention Localization for Offline Handwritten Text. Neural Processing Letters, April, 2023, DOI: https://doi.org/10.1007/s11063-023-11258-5
[Accepted Manuscript]
[SharedIt]
[DOI]
[Bib]
[Code and pre-trained models]
[PUCIT-OHUL Dataset]
[Demo]
|
|
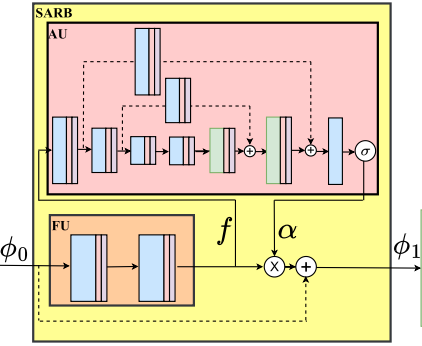
SARGAN: Spatial Attention-based Residuals for Facial Expression Manipulation
with Arbish Akram
Encoder-decoder based architecture has been widely used in the generator of generative adversarial networks for facial manipulation. However, we observe that the current architecture fails to recover the input image color, rich facial details such as skin color or texture and introduces artifacts as well. In this paper, we present a novel method named SARGAN that addresses the above-mentioned limitations from three perspectives. First, we employed spatial attention-based residual block instead of vanilla residual blocks to properly capture the expression-related features to be changed while keeping the other features unchanged. Second, we exploited a symmetric encoder-decoder network to attend facial features at multiple scales. Third, we proposed to train the complete network with a residual connection which relieves the generator of pressure to generate the input face image thereby producing the desired expression by directly feeding the input image towards the end of the generator. Both qualitative and quantitative experimental results show that our proposed model performs significantly better than state-of-the-art methods. In addition, existing models require much larger datasets for training but their performance degrades on out-of-distribution images. While SARGAN can be trained on smaller facial expressions datasets, which generalizes well on out-of-distribution images including human photographs, portraits, avatars and statues.
Akram, Arbish, and Nazar Khan. SARGAN: Spatial Attention-based Residuals for Facial Expression Manipulation. IEEE Transactions on Circuits and Systems for Video Technology, 33 (10), 5433-5443, March 10, 2023, DOI: https://doi.org/10.1109/TCSVT.2023.3255243
[arXiv]
[DOI]
[Bib]
[Code and pre-trained model]
|
|
Clustering-based Detection of Debye-Scherrer Rings
with Rabia Sirhindi
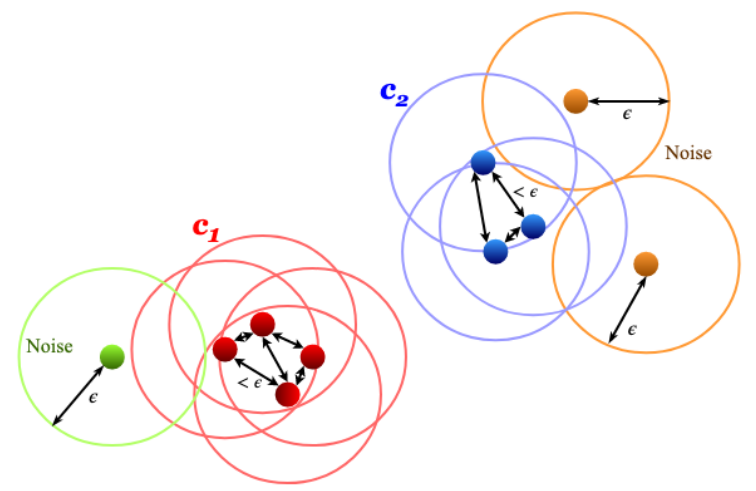
Calibration of the X-ray powder diffraction experimental setup is a crucial step before data reduction and analysis, and requires correctly extracting individual Debye-Scherrer rings from the 2D XRPD image. We approach this problem using a clustering-based machine learning framework, thus interpreting each ring as a cluster. This allows automatic identification of Debye-Scherrer rings without human intervention and irrespective of detector type and orientation. Various existing clustering techniques are applied to XRPD images generated from both orthogonal and non-orthogonal detectors and the results are visually presented for images with varying inter-ring distances, diffuse scatter and ring graininess. The accuracy of predicted clusters is quantitatively evaluated using an annotated gold standard and multiple cluster analysis criteria. Our results demonstrate the superiority of density-based and spectral clustering for the detection of Debye-Scherrer rings. Moreover, the given algorithms impose no prior restrictions on detector parameters such as sample-to-detector distance, alignment of the center of diffraction pattern or detector type and tilt, as opposed to existing automatic detection approaches.
Sirhindi, R., and Khan, N.Clustering-based Detection of Debye-Scherrer Rings. ASME. J. Comput. Inf. Sci. Eng. January, 2023, DOI: https://doi.org/10.1115/1.4056568
[DOI]
[Bib]
|

|
Mitigating the Class Overlap Problem in Discriminative Localization: COVID-19 and Pneumonia Case Study
with Edward Verenich, M. G. Sarwar Murshed, Alvaro Velasquez and Faraz Hussain
Early detection and diagnosis of the SARS-CoV-2 virus which causes COVID-19 remains a difficult and time-sensitive process. Though progress has been made in the development and administration of tests, the time required to obtain a confident response can be prohibitive in areas of dense outbreaks. For these reasons, there has been great interest in adopting machine learning solutions to detect COVID-19 in prospective patients and aid clinicians in its localization. However, the adoption of deep learning approaches for these tasks is faced with multiple key challenges. In this work, we present a novel discriminative localization approach based on the computation of Class Activation Maps (CAMs) that addresses the problem of class overlap and imbalance within training data. In particular, we train a Convolutional Neural Network (CNN) on viral pneumonia and COVID-19 labels and compute the difference in scaled activations of the features in the last convolutional layer of the CNN for both classes. In doing so, we exploit the feature similarity between the two diseases for training purposes, thereby mitigating issues arising due to the scarcity of COVID-19 data. In models with overlapping classes, this can yield a neuron co-adaptation problem wherein the model is less confident in the outputs of similar classes, resulting in large CAMs with decreased localization certainty. Increasing the final mapping resolution of the last convolutional layer can reduce the overall area of such CAMs, but does not address class overlap, because CAMs computed for such classes exhibit significant spatial overlap, making it difficult to distinguish which spatial regions contribute the most to a specific target class. Our approach mitigates this by computing directed differences in scaled activations of pneumonia and COVID-19 CAMs, amplifying these differences, and projecting the results on to the original image in order to aid clinicians in the early detection of COVID-19. Specifically, our method clearly delineates spatial regions of an image that the classifier model considers as the most relevant for a given classification, even when standard CAMs for multiple classes within the model exhibit significant spatial overlap due to similarity in feature activations.
Verenich, E., Murshed, M.G.S., Khan, N., Velasquez, A., Hussain, F. Mitigating the Class Overlap Problem in Discriminative Localization: COVID-19 and Pneumonia Case Study. In: Sayed-Mouchaweh, M. (eds) Explainable AI Within the Digital Transformation and Cyber Physical Systems., pp. 125-151, Springer, Cham, 2022. https://doi.org/10.1007/978-3-030-76409-8_7
[Manuscript]
[Bib]
|

|
Efficient Deployment of Deep Learning Models on Autonomous Robots in the ROS Environment
with M. G. Sarwar Murshed, James J. Carroll and Faraz Hussain
Autonomous robots are often deployed in applications to continually monitor changing environments such as supermarket floors or inventory monitoring, patient monitoring, and autonomous driving. With the increasing use of deep learning techniques in robotics, a large number of robot manufacturing companies have started adopting deep learning techniques to improve the monitoring performance of autonomous robots. The Robot Operating System (ROS) is a widely used middleware platform for building autonomous robot applications. However, the deployment of deep learning models to autonomous robots using ROS remains an unexplored area of research. Most recent research has focused on using deep learning techniques to solve specific problems (e.g., shopping assistant robots, autopilot systems, automatic annotation of 3D maps for safe flight). However, integrating the data collection hardware (e.g., sensors) and deep learning models within ROS is difficult and expensive in terms of computational power, time, and energy (battery). To address these challenges, we have developed EasyDLROS, a novel framework for robust deployment of pre-trained deep learning models on robots. Our framework is open-source, independent of the underlying deep learning framework, and easy to deploy. To test the performance of EasyDLROS, we deployed seven pre-trained deep learning models for hazard detection on supermarkets floors in a simulated environment and evaluated their performances. Experimental results show that our framework successfully deploys the deep learning models on ROS environment.
M. G. Sarwar Murshed, James J. Carroll, Nazar Khan, Faraz Hussain. Efficient Deployment of Deep Learning Models on Autonomous Robots in the ROS Environment, In: Wani, M.A., Raj, B., Luo, F., Dou, D. (eds) Deep Learning Applications, Volume 3, pp. 215-243. Advances in Intelligent Systems and Computing, vol 1395. Springer, Singapore, 2022. https://doi.org/10.1007/978-981-16-3357-7_9
[Manuscript]
[Bib]
[Code]
|
|
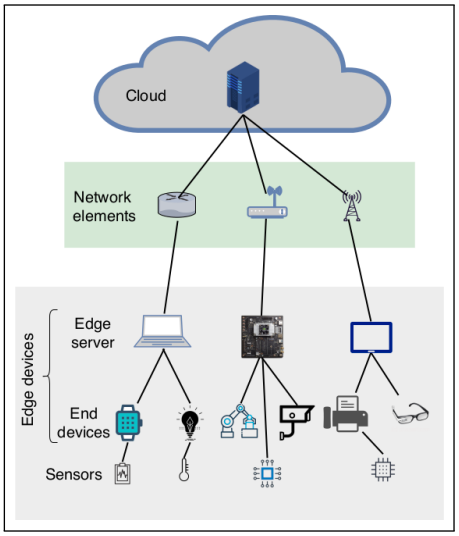
Machine Learning at the network edge: A survey
with Murshed, M. S., Murphy, C., Hou, D., Ananthanarayanan, G., & Hussain, F.
Resource-constrained IoT devices, such as sensors and actuators, have become ubiquitous in recent years. This has led to the generation of large quantities of data in real-time, which is an appealing target for AI systems. However, deploying machine learning models on such end-devices is nearly impossible. A typical solution involves offloading data to external computing systems (such as cloud servers) for further processing but this worsens latency, leads to increased communication costs, and adds to privacy concerns. To address this issue, efforts have been made to place additional computing devices at the edge of the network, i.e close to the IoT devices where the data is generated. Deploying machine learning systems on such edge computing devices alleviates the above issues by allowing computations to be performed close to the data sources. This survey describes major research efforts where machine learning systems have been deployed at the edge of computer networks, focusing on the operational aspects including compression techniques, tools, frameworks, and hardware used in successful applications of intelligent edge systems.
Murshed, M. S., Murphy, C., Hou, D., Khan, N., Ananthanarayanan, G., & Hussain, F. Machine learning at the network edge: A survey, ACM Computing Surveys (CSUR), 54(8), 1-37, 2021.
[Manuscript]
[arXiv]
[Bib]
|

|
Pixel-based Facial Expression Synthesis
with Arbish Akram
Facial expression synthesis has achieved remarkable advances with the advent of Generative Adversarial Networks (GANs). However, GAN-based approaches mostly generate photo-realistic results as long as the testing data distribution is close to the training data distribution. The quality of GAN results significantly degrades when testing images are from a slightly different distribution. Moreover, recent work has shown that facial expressions can be synthesized by changing localized face regions. In this work, we propose a pixel-based facial expression synthesis method in which each output pixel observes only one input pixel. The proposed method achieves good generalization capability by leveraging only a few hundred training images. Experimental results demonstrate that the proposed method performs comparably well against state-of-the-art GANs on in-dataset images and significantly better on out-of-dataset images. In addition, the proposed model is two orders of magnitude smaller which makes it suitable for deployment on resource-constrained devices.
Arbish Akram and Nazar Khan, Pixel-based Facial Expression Synthesis, 25th International Conference on Pattern Recognition (ICPR 2020), Milan Italy, January 10-15 2021.
[Project page]
[Manuscript]
[arXiv]
[Presentation]
[Poster]
[Bib]
[Code]
|
|
|
Resource-aware On-device Deep Learning for Supermarket Hazard Detection
with M. G. Sarwar Murshed, James J. Carroll and Faraz Hussain
Supermarkets need to implement safety measures to create a safe environment for shoppers
and employees. Many of these injuries, such as falls, are caused by a lack of safety precautions.
Such incidents are preventable by timely detection of hazardous conditions such as undesirable
objects on supermarket floors. In this paper, we describe EdgeLite, a new lightweight deep
learning model specifically designed for local and fast inference on edge devices which have
limited memory and compute power. We show how EdgeLite was deployed on three different edge devices
for detecting hazards in images of supermarket floors. On our dataset of supermarket floor hazards,
EdgeLite outperformed six state-of-the-art object detection models in terms of accuracy when
deployed on the three small devices. Our experiments also showed that energy consumption,
memory usage, and inference time of EdgeLite were comparable to that of the baseline
models. Based on our experiments, we provide recommendations to practitioners for overcoming
resource limitations and execution bottlenecks when deploying deep learning models in settings
involving resource-constrained hardware.
M. G. Sarwar Murshed, James J. Carroll, Nazar Khan, Faraz Hussain. Resource-aware On-device
Deep Learning for Supermarket Hazard Detection, 2020 19th IEEE International Conference
on Machine Learning and Applications (ICMLA), IEEE, Dec. 2020.
[Manuscript]
[Bib]
[Code]
|
|
|
Improving Explainability of Image Classification in Scenarios with Class Overlap: Application to
COVID-19 and Pneumonia
with Edward Verenich, Alvaro Velasquez and Faraz Hussain
Trust in predictions made by machine learning models is increased if the model generalizes well on previously unseen samples and when inference is accompanied by cogent explanations of the reasoning behind predictions. In the image classification domain, generalization can be assessed through accuracy, sensitivity, and specificity. Explainability can be assessed by how well the model localizes the object of interest within an image. However, both generalization and explainability through localization are degraded in scenarios with significant overlap between classes. We propose a method based on binary expert networks that enhances the explainability of image classifications through better localization by mitigating the model uncertainty induced by class overlap. Our technique performs discriminative localization on images that contain features with significant class overlap, without explicitly training for localization. Our method is particularly promising in real-world class overlap scenarios, such as COVID-19 and pneumonia, where expertly labeled data for localization is not readily available. This can be useful for early, rapid, and trustworthy screening for COVID-19.
Edward Verenich, Alvaro Velasquez, Nazar Khan, and Faraz Hussain. Improving Explainability of Image Classification in Scenarios with Class Overlap: Application to
COVID-19 and Pneumonia, 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA) Special Session, IEEE, Dec. 2020.
[arXiv]
[Bib]
|

|
Automatic recognition of handwritten Urdu sentences
with Tayaba Anjum
Compared to derivatives from Latin script, recognition of derivatives from Arabic hand-written script is a complex task due to the presence of two-dimensional structure, context-dependent shape
of characters, high number of ligatures, overlap of characters, and placement of diacritics. While significant attempts exist for Latin and Arabic scripts, very
few attempts have been made for offline, handwritten, Urdu script. In this paper, we introduce a large, annotated dataset of handwritten Urdu sentences. We also present a
methodology for the recognition of offline handwritten Urdu text lines. A deep learning based encoder/decoder framework with attention mechanism is
used to handle two-dimensional text structure. While existing approaches report only character level accuracy, the proposed model improves on BLSTM-based
state-of-the-art by a factor of 2 in terms of character level accuracy and by a factor of 37 in terms of word level accuracy. Incorporation of attention before a
recurrent decoding framework helps the model in looking at appropriate locations before classifying the next character and therefore results in a higher word level accuracy.
Tayaba Anjum and Nazar Khan, An attention based method for offline handwritten Urdu text recognition, 17th International Conference on Frontiers in Handwriting Recognition (ICFHR 2020), Sep 7-10, 2020.
[Project page]
[Manuscript]
[Presentation]
[Bib]
[Code]
[PUCIT-OHUL Dataset]
|

|
Masked Regression for Facial Expression Synthesis
with Arbish Akram, Arif Mehmood, Sania Ashraf and Kashif Murtaza
Compared to facial expression recognition, expression synthesis requires a very high-dimensional
mapping. This problem exacerbates with increasing image sizes and limits
existing expression synthesis approaches to relatively small images. We observe that
facial expressions often constitute sparsely distributed and locally correlated changes
from one expression to another. By exploiting this observation, the number of
parameters in an expression synthesis model can be significantly reduced. Therefore,
we propose a constrained version of ridge regression that exploits the local and sparse
structure of facial expressions. We consider this model as masked regression for
learning local receptive fields. In contrast to the existing approaches, our proposed
model can be efficiently trained on larger image sizes. Experiments using three publicly
available datasets demonstrate that our model is significantly better than L0, L1 and
L2-regression, SVD based approaches, and kernelized regression in terms of mean-
squared-error, visual quality as well as computational and spatial complexities. The
reduction in the number of parameters allows our method to generalize better even
after training on smaller datasets. The proposed algorithm is also compared with state-
of-the-art GANs including Pix2Pix, CycleGAN, StarGAN and GANimation. These GANs
produce photo-realistic results as long as the testing and the training distributions are
similar. In contrast, our results demonstrate significant generalization of the proposed
algorithm over out-of-dataset human photographs, pencil sketches and even animal
faces.
Nazar Khan, Arbish Akram, Arif Mehmood, Sania Ashraf and Kashif Murtaza, Masked Linear Regression for Learning Local Receptive Fields for Facial Expression Synthesis, International Journal of Computer Vision (IJCV), 128(5), 2020.
[Paper]
[ReadCube version]
[Manuscript]
[Presentation]
[Bib]
[Matlab Code]
[Python Code]
|
|
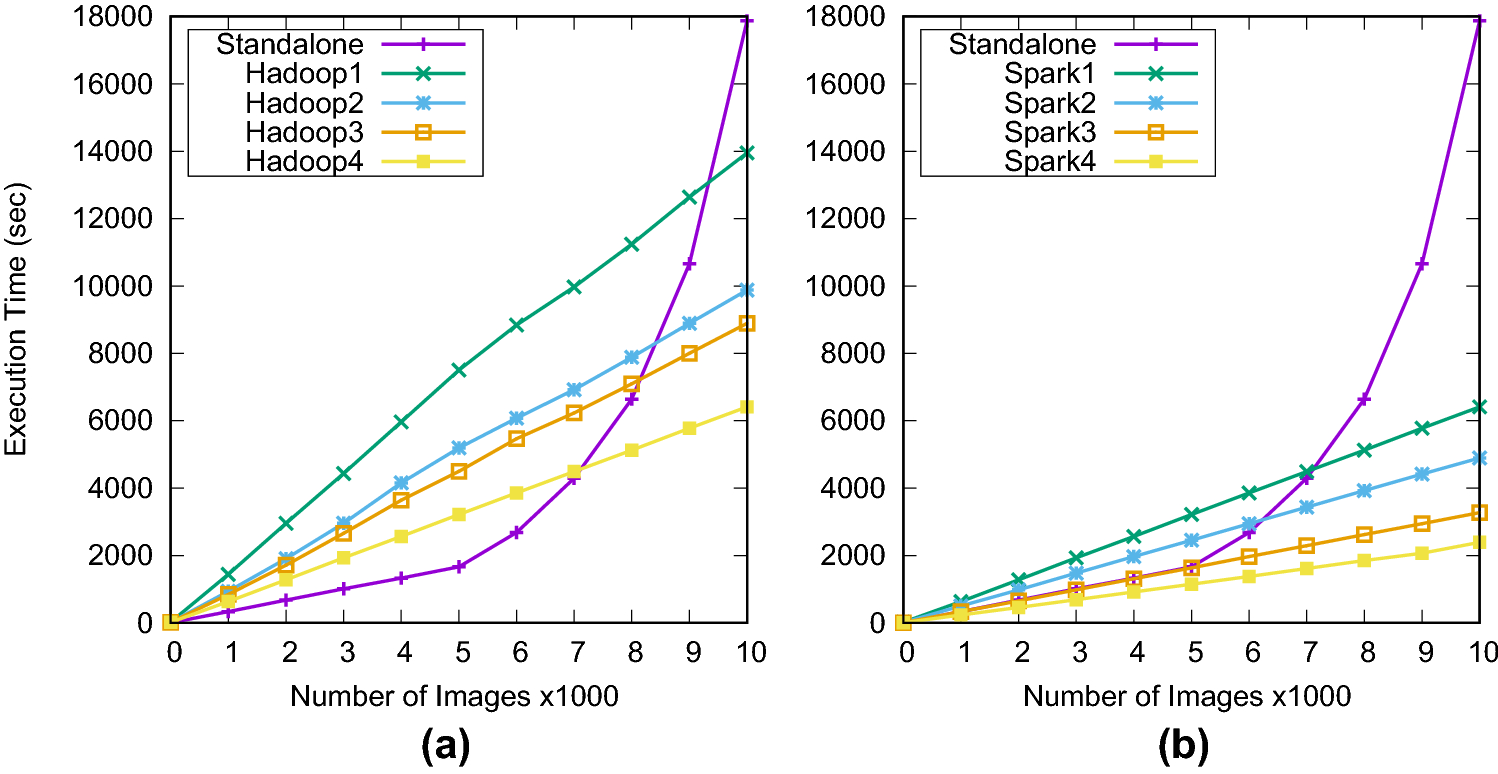
Canny and Hough on Hadoop and Spark
with Bilal Iqbal, Waheed Iqbal, Arif Mahmood and Abdelkarim Erradi
Nowadays, video cameras are increasingly used for surveillance, monitoring, and activity recording. These cameras generate high resolution image and video data at large scale. Processing such large scale video streams to extract useful information with time constraints is challenging. Traditional methods do not offer scalability to process large scale data. In this paper, we propose and evaluate cloud services for high resolution video streams in order to perform line detection using Canny edge detection followed by Hough transform. These algorithms are often used as preprocessing steps for various high level tasks including object, anomaly, and activity recognition. We implement and evaluate both Canny edge detector and Hough transform algorithms in Hadoop and Spark. Our experimental evaluation using Spark shows an excellent scalability and performance compared to Hadoop and standalone implementations for both Canny edge detection and Hough transform. We obtained a speedup of 10.8x and 9.3x for Canny edge detection and Hough transform respectively using Spark. These results demonstrate the effectiveness of parallel implementation of computer vision algorithms to achieve good scalability for real-world applications.
Bilal Iqbal, Waheed Iqbal, Nazar Khan, Arif Mahmood and Abdelkarim Erradi, Canny edge detection and Hough transform for high resolution video streams using Hadoop and Spark, Cluster Computing 23(1), 2020, pp 397-408.
[Paper]
[Bib]
|
|
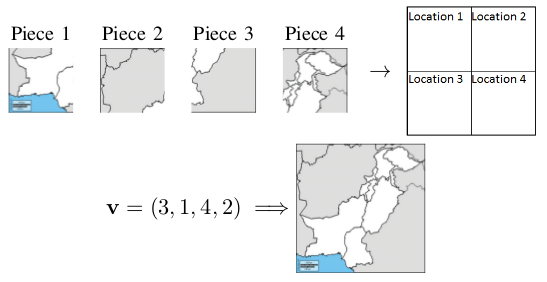
Adversarial Placement Vector Generation
with Ayesha Rafique and Tauseef Iftikhar
Automated jigsaw puzzle solving is a challenging problem with numerous scientific applications. We explore whether a Generative Adversarial Network (GAN) can output jigsaw piece placements. State-of-the-art GANs for image-to-image translation cannot solve the jigsaw problem in an exact fashion. Instead of learning image-to-image mappings, we propose a novel piece-to-location mapping problem and present a trainable generative model for producing output that can be interpreted as the placement of jigsaw pieces. This represents a first step in developing a complete learning-based generative model for piece-to-location mappings. We introduce four new evaluation measures for the quality of output locations and show that locations generated by our model perform favorably.
A. Rafique, T. Iftikhar and N. Khan, Adversarial Placement Vector Generation, 2nd International Conference on Advancements in Computational Sciences (ICACS), 2019.
[Paper]
[Presentation]
,[DOI]
[Bib]
|
|
|
Incremental Ellipse Detection
with Saadia Shahzad,
Zubair Nawaz and
Claudio Ferrero
Projections of spherical/ellipsoidal objects appear as ellipses in 2-D images. Detection of these ellipses enables information about the objects to be extracted. In some applications, images contain ellipses with scattered data i.e. portions of an ellipse can have significant gaps in-between. We initially group pixels to get small connected regions. Then we use an incremental algorithm to grow these scattered regions into ellipses. In our proposed algorithm, we start growing a region by selecting neighbours near this region and near the best-fit ellipse of this region. After merging the neighbours into the original region, a new ellipse again. This proceeds until convergence. We evaluate our method on the problem of detecting ellipses in X-ray diffraction images where diffraction patterns appear as so-called Debye-Scherrer rings. Detection of these rings allows calibration of the experimental setup.
S. Shahzad, N. Khan, Z. Nawaz and C. Ferrero, Automatic Debye-Scherrer elliptical ring extraction via a computer vision approach, Journal of Synchrotron Radiation, 25(2), 2018, 439--450.
[Paper]
[Bib]
[Code]
|


|
Click-free, Video-based Document Capture
with Waqas Tariq
We propose a click-free method for video-based digitization of multi-page documents. The work is targeted at the non-commercial, low-volume, home user. The document is viewed through a mounted camera and the user is only required to turn pages manually while the system automatically extracts the video frames representing stationary document pages. This is in contrast to traditional document conversion approaches such as photocopying and scanning which can be time-consuming, repetitive, redundant and can lead to document deterioration.
Main contributions of our work are i) a 3-step method for automatic extraction of unique, stable and clear document pages from video, ii) a manually annotated data set of 37 videos consisting of 726 page turn events covering a large variety of documents, and iii) a soft, quantitative evaluation criterion that is highly correlated with the hard F1-measure. The criterion is motivated by the need to counter the subjectivity in human marked ground truth for videos. On our data set, we report an F1-measure of 0.91 and a soft score of 0.94 for the page extraction task.
W. Tariq and N. Khan, Click-Free, Video-Based Document Capture -- Methodology and Evaluation, CBDAR 2017.
[Paper] [Presentation] [Bib] [Dataset] [Errata]
|
|
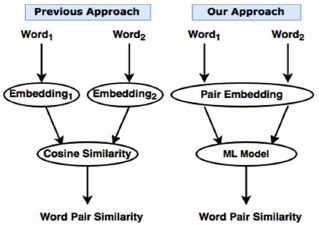
Word Pair Similarity
with Asma Shaukat
We present a novel approach for computing similarity of English word pairs. While many previous approaches compute cosine similarity of individually computed word embeddings, we compute a single embedding for the word pair that is suited for similarity computation. Such embeddings are then used to train a machine learning model. Testing results on MEN and WordSim-353 datasets demonstrate that for the task of word pair similarity, computing word pair embeddings is better than computing word embeddings only.
A. Shaukat and N. Khan, New Word Pair Level Embeddings to Improve Word Pair Similarity, ICDAR, WML 2017.
[Paper] [Presentation] [Bib]
|


|
LSM: Perceptually Accurate Line Segment Merging
with Naila Hamid
Existing line segment detectors tend to break up perceptually distinct line segments into multiple segments. We propose an algorithm for merging such broken segments to recover the original perceptually accurate line segments. The algorithm proceeds by grouping line segments on the basis of angular and spatial proximity. Then those line segment pairs within each group that satisfy unique, adaptive mergeability criteria are successively merged to form a single line segment. This process is repeated until no more line segments can be merged. We also propose a method for quantitative comparison of line segment detection algorithms. Results on the York Urban dataset show that our merged line segments are closer to human-marked ground-truth line segments compared to state-of-the-art line segment detection algorithms.
N. Hamid and N. Khan, LSM: Perceptually Accurate Line Segment Merging, Journal of Electronic Imaging, 25(6), 2016
[Project page] [PDF] [Bib] [Code]
|
|
Video-based Vehicular Statistics Estimation
with Nausheen Qaiser
A method for automatically estimating vehicular statistics from video. Accurately locating vehicles in a video becomes a challenging task when the brightness is varying and when the vehicles are occluded by each other. We are looking towards:
- accurate tracking of vehicles in different scenarios such as
- slow/fast-moving traffic,
- stop and go traffic, and
- light variation and occlusion
- real-time vehicle tracking and speed computation.
Currently, the algorithm gives 19.3% error in speed estimates for a video capturing 3 lanes and containing about 80 vehicles from fast-moving to slow-moving ones, and stop-and-go traffic.
|

|
Automated Rural Map Parsing For Land Record Digitization
with Tauseef Iftikhar
A framework for automated mauza-map stitching from digital images of Colonial-era, hand-drawn cadastral maps. The framework
- is automated,
- determines its own failure, and therefore
- transfers to a semi-automated system.
In order to assist the stitching process, we also automatically extract meta-data from the map. Initially funded by DAAD under the grant for the MARUP project.
|
| Input |
Previous 1D Method |
Our Method |
|
|
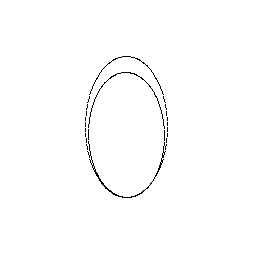
|
|
A Fast and Improved Hough Transform based Ellipse Detector using 1D Parametric Space
with Umar Farooq
There are many approaches to detect ellipses from images. The standard Hough Transform based approach depends on the number of parameters and requires a five dimensional accumulator array to gather votes for the five parameters of an ellipse. We propose a modified HT based ellipse detector which requires a 1D parametric space. It overcomes the weaknesses of previous 1D approaches which include i) missed detections when multiple ellipses are partially overlapped, ii) redundant and false detections. We overcome these weaknesses while also reducing the execution time of the algorithm by exploiting gradient information of edge pixels.
|


|
Automated Road Condition Monitoring
with Naila Hamid, Kashif Murtaza and Raqib Omer
A framework for automated road condition monitoring. The research emphasis is on simultaneous incorporation of chromo-geometric information. Accordingly, color and vanishing point based road detection is performed. The condition of the road area is then determined using a hierarchical classification scheme to deal with the non-robustness of using color as a feature.
|